Build ML Models on the Highest Quality Data: Meet sCompute

Greetings of the day, Data Scientists!
I hope you’re all doing well.
When you’re thinking about data science, what’s the first platform that comes to mind? For me, it’s Anaconda. Don’t worry if this isn’t your answer. Being popular does not mean that everyone must use it. But that’s not the point of this article. We can debate this in some future articles😅 Without wasting more time, let’s jump into the topic.
Every year, the team behind Anaconda releases a whitepaper called "State of Data Science". This is a report generated from the results of a survey that "looks at actionable issues within the data science, machine learning, and artificial intelligence industries, like open-source security, the talent dilemma, ethics and bias, and more."
Here, I am only interested in one question: "How do data scientists spend their time?"
Here’s a chart that summarizes the answer:
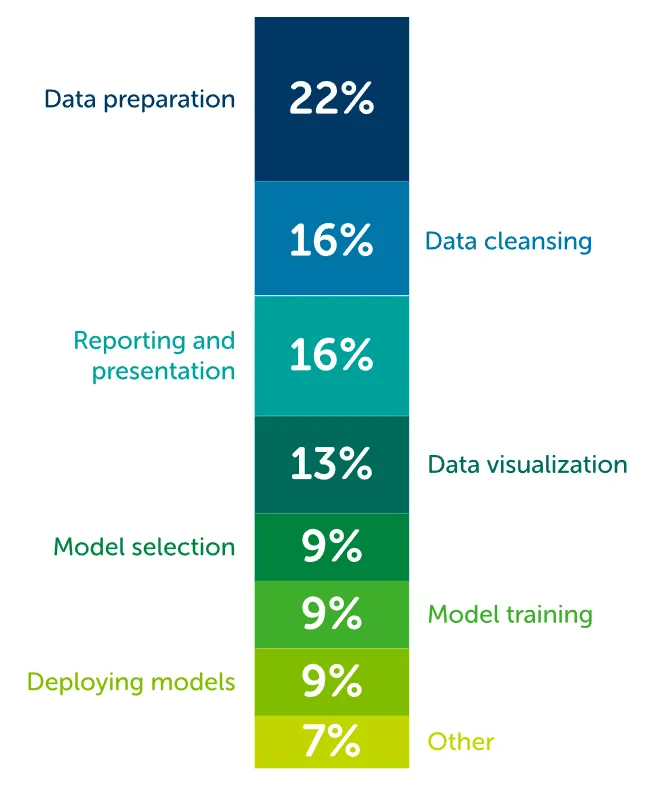

If you combine the top two blocks, data scientists spend roughly 38% of their time preparing and cleaning the data. Why is it so?
Well, as a beginner myself in data science, I can be a little wrong here. But the quality of the data matters a lot. The greater the quality, the greater the amount of time spent processing and cleaning. These were the average figures. I was even able to find figures that were as high as 80%. However, I can’t really prove the accuracy of the figures.
You see, collecting data is a messy process. If you’re a student, you will be able to find plenty of datasets on websites like Kaggle. But businesses find it hard to collect data due to privacy and security concerns. Internet users are now aware of their privacy and take it very seriously. But if people refuse to share their data, how can businesses find high-quality data? We are in an era in which big data is the new oil, and businesses with access to data have significant leverage over those who don’t. So, what’s the solution?
Well, there is a solution. What if businesses collect the data with consent from the user in return for a share of the revenue generated from the data? This is what Swash is trying to solve. Learn more about it here. In a nutshell, you as an internet user could earn a passive income if you choose to share your data, which will never hurt your privacy since it will be fully anonymized.
If you want to try out the extension, here’s my referral link
Now, you should be able to relate to the title of this article.
Swash is building an ecosystem of products. One such product is sCompute. And we are now going to test it out. Excited? So am I. Now, we need to set up a few things before starting:
Non-custodial wallets like MetaMask
Browser with an active internet connection
Unless you’re reading this article in an unusual format, like in a read or printed format, the second point should not be an issue. You can find hundreds of tutorials on the first one. It will hardly take two minutes. Hurry up; I am waiting.
On a side note, you don’t need funds to test out sCompute. This is just for educational purposes. If you’re serious about testing everything about sCompute, you will need some funds in your wallet.
So, head over to this link. You should see a page like this:
Now, click on GET STARTED NOW at the top of the page.
Click on Sign in at the top of the page. Choose MetaMask if you have a wallet installed on your browser; otherwise, use Wallet Connect if you want to use a wallet installed on your mobile device. Sign the signature, and you’re good to go.
Now, we will be lightly touching all the features of sCompute. For more details, you can check out this blog from the official Swash team.
You will be greeted with this beautiful dashboard:
At the top right corner, you will get the option to log out of sCompute. I think the level of privacy should be pretty evident now. They don’t even ask for email addresses, and wallet addresses are fully anonymous.
Now, let’s try to get a demo data file to assess the quality of the data. Go to Data Provider -> Add data request.
As you can see, you can filter out the data you’re interested in to keep costs down. You can choose from a variety of data types, which are pretty self-explanatory:
Visitation
Search Request
Search Result
Shopping
For this tutorial, I am choosing Search Results. Set the repeat type to Once. Give the output file a name of your choice. Select a date range. You can set any range since the sample file will be the same regardless of the time range.
Now, let’s move on to Data Column Selection. Let’s select a few columns. I am selecting the following 3:
SEARCH_CATEGORY
RESULT_TYPE
BROWSER_NAME
You can add more conditions, but none of them will be reflected in the sample file. So, I will keep the rest the same.
Once we’re done, we should be able to see something like this:
If you go to Actions -> Purchase, you should be able to see the price of the data.
This should be enough to convince you to download the Swash extension. Here’s the link to do so if you haven’t already.
Now, in Actions, click on Download Sample. Here’s how it looks for me:
See, no missing values!
Let’s explore a little more. Go to Execution -> Files. This is where you’re going to drop your code files. I am not really sure about how many languages are supported, but I am 100% sure that Python files will work.
Since we don’t have funds, we can’t do anything more than explore. Let’s explore the pipelines section before wrapping this up.
Go to Execution -> Pipelines. Click on Add. Now, can you see the sheer number of frameworks and algorithms supported?
If you have the funds, you can always try things out.
Let’s wrap this up. sCompute is creating a new revolution. Maybe, in the coming months, data scientists will be spending far less time on data cleaning and pre-processing as the popularity of Swash increases. Now, here comes the million-dollar question. Is sCompute perfect? Well, I would say it’s almost perfect. It’s in its nascent stages, so I can’t complain much. Maybe there should be in-house visualization tools as well, which could be even more beneficial. Anyway, if you liked this tutorial, feel free to test sCompute out. Show some love by sharing this article. Also, consider downloading the Swash extension.
Thank you for reading!